프로그래밍 세계를 탐구합시다.
< 데이터프레임 행단위/열단위 합치기 >
import pandas as pd
행단위 합치기
### 임시 데이터 생성
# 임시 데이터
data = [["Dog", 3], ["Cat", 5], ["Tiger", 2]]
index = [0, 1, 2]
columns = ["동물", "나이"]
df_temp1 = pd.DataFrame(data,
index=index,
columns=columns)
df_temp1

### 임시 데이터 생성
# 임시 데이터
data = [["집", 3], ["초원", 5], ["초원", 2]]
index = [0, 1, 2]
columns = ["사는곳", "뿔의갯수"]
df_temp2 = pd.DataFrame(data,
index=index,
columns=columns)
df_temp2

df_temp1과 df_temp2를 행단위로 합치기(행으로 추가)
### df_temp1과 df_temp2를 행단위로 합치기(행으로 추가)
pd.concat([df_temp1, df_temp2], axis=0, ignore_index=True)

< 열단위로 합치기 >
### 열단위로 합칠 때는 행의 갯수가 동일해야 한다
pd.concat([df_temp1, df_temp2], axis=1)

< 열단위 합치기 : 키값을 이용해서 합치는 방식 >
### 임시 데이터 생성
# 임시 데이터
data1 = {"국적코드" : [1001, 1002, 1003],
"국가" : ["한국", "미국", "인도"]}
df_info1 = pd.DataFrame(data1)
data2 = {"국적코드" : [1001, 1001, 1005],
"인구" : [100, 200, 300]}
df_info2 = pd.DataFrame(data2)
df_info1
df_info2

국적코드가 같은 값들에 대해서 합치기
### 국적코드가 같은 값들에 대해서 합치기
# - 기준은 df_info1
pd.merge(left=df_info1,
right=df_info2,
how="inner",
left_on="국적코드",
right_on="국적코드")

국적코드가 같은 값은 같은대로, 같지 않으면 NaN으로 합치기
### 국적코드가 같은 값은 같은대로, 같지 않으면 NaN으로 합치기
# - 기준은 df_info1
pd.merge(left=df_info1,
right=df_info2,
how="left",
left_on="국적코드",
right_on="국적코드")

< 전처리 >
결측치 처리
### bicycle.csv 파일 읽어들이기
df = pd.read_csv("./data/bicycle.csv", encoding="euc-kr")
df

결측데이터 확인하기
### 결측데이터 확인하기
df.info()

### 결측치 데이터 확인하기
# - 결측 데이터 값은 True, 정상 데이터는 False
df.isnull()

### 결측치가 아닌 데이터 확인하기
df.notnull()

< 결측치 처리 방법 >
1. 결측치가 있는 부분의 데이터를 사용할지/말지 결정
2. 사용 안 한다면 -> 컬럼과 행 중에 어느 부분을 제거할지 결정
3. 사용한다면 -> 어떻게 대체할 지 결정
(대체 방법)
3.1. 결측치가 있는 해당 컬럼의 평균으로 모두 대체
3.2. 범주형 데이터인 경우에는 범주의 비율대비로 대체
3.3. 숫자값인 경우 모두 0으로 대체
3.4. 결측데이터가 속한 주변 컬럼들의 데이터 유형과 유사한 데이터들의 평균으로 대체
3.5. 결측치가 있는 컬럼의 직전/직후 데이터의 평균으로 대체
< 결측데이터 현황 확인 >
컬럼별 결측 현황
### 결측데이터 현황 확인
# 컬럼별 결측 현황
# - sum(0) : 0의 의미는 각 열의 행단위를 의미함
df.isnull().sum(0)

행별 결측 현황
# 행별 결측 현황
# - sum(0) : 0의 의미는 각 행의 컬럼 단위를 의미함
df.isnull().sum(1)

< 결측데이터 삭제하기 >
결측치가 있는 모든 행들 삭제하기
### 결측치가 있는 모든 행들 삭재하기
df_drop = df.dropna(axis=0)
df_drop.info()

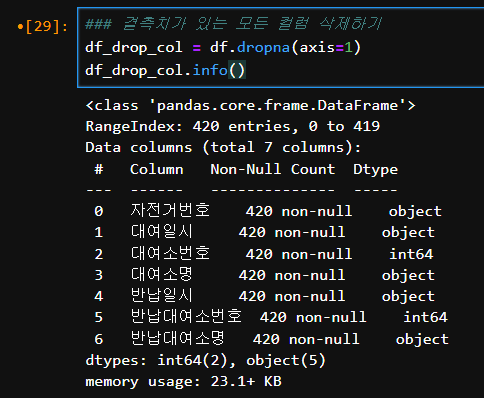
결측치가 있는 모든 컬럼 삭제하기
### 결측치가 있는 모든 컬럼 삭제하기
df_drop_col = df.dropna(axis=1)
df_drop_col.info()
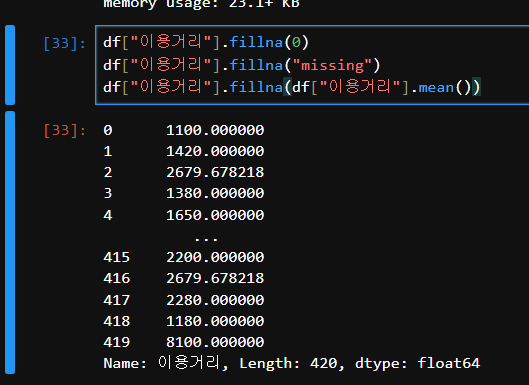
df["이용거리"].fillna(0)
df["이용거리"].fillna("missing")
df["이용거리"].fillna(df["이용거리"].mean())
< 중복데이터 처리 >
- keep : first, last, False
keep : 중복 중에 몇 번째 중복을 False(남겨 둘 것인지)로 할 것인지
중복 중에 첫번째는 False, 나머지 뒤에 중복들은 모두 True로
first : 첫번째인 False(enlWhr 중복 데이터는 모두 True) -> 기본값, 생략 가능
last : 마지막만 False(앞쪽 중복 데이터는 모두 True)
False : 중복데이터 전체 True
df["이용거리"]
### 중복데이터가 있는 행의 위치 확인하기
df[df.duplicated(["이용거리"])]
### keep : 중복 중에 몇 번째 중복을 False(남겨 둘 것인지)로 할 것인지
### 중복 중에 첫번째는 False, 나머지 뒤에 중복들은 모두 True로
# - keep : first, last, False
# first : 첫번째인 False(enlWhr 중복 데이터는 모두 True) -> 기본값, 생략 가능
# last : 마지막만 False(앞쪽 중복 데이터는 모두 True)
# False : 중복데이터 전체 True
df.duplicated(["이용거리"], keep="first")
df.duplicated(["이용거리"], keep="last")
df.duplicated(["이용거리"], keep="False")

df.duplicated(["이용거리"], keep="first").value_counts()

### 중복 데이터는 사용할지 말지만 결정하면 됩니다.
df.drop_duplicates(["이용거리"])

< 이상 데이터 처리 >
<이상 데이터 처리 순서>
1. 결측치 처리가 선행되어야 합니다.
- 결측치도 데이터로 인식되기 때문에
2. 이상데이터에는 범주형, 숫자형 데이터 처리 방식이 다름
- 일반적으로 이상데이터는 숫자형 데이터 처리를 주로 합니다.
3. 이상 데이터 확인은 시각화(boxplot)를 통해서 확인합니다.
4. 실제 처리는 계산에 의해 처리됩니다.
사용할 데이터 읽어들이기
### 사용할 데이터 읽어들이기
df = pd.read_csv("./data/bicycle_out.csv", encoding="euc-kr")
df.info()

결측치 처리하기
### 결측치 처리하기
df["대여거치대"] = df["대여거치대"].fillna(int(df["대여거치대"].mean()))
df["반납거치대"] = df["반납거치대"].fillna(int(df["반납거치대"].mean()))
df["이용시간"] = df["이용시간"].fillna(int(df["이용시간"].mean()))
df["이용거리"] = df["이용거리"].fillna(int(df["이용거리"].mean()))
df.info()

행단위 중복체크
### 행단위 중복체크
df.duplicated().value_counts()

이상데이터 확인하기
### 이상데이터 확인하기
df.describe()

나이 데이터를 기준으로 이상데이터 시각적으로 확인하기
- 박스 위쪽 선 : Max Outliers
- 박스 위쪽 선 : Min Ounliers
- 이상치로 의심되는 데이터 : Max 및 Min Ounliers를 벗어난 데이터들
### 나이 데이터를 기준으로 이상데이터 시각적으로 확인하기
# - 박스플롯(boxplot)을 이용해서 시각화 합니다.
plt.boxplot(df["나이"])
plt.show()
"""
- 박스 위쪽 선 : Max Outliers
- 박스 위쪽 선 : Min Ounliers
- 이상치로 의심되는 데이터 : Max 및 Min Ounliers를 벗어난 데이터들
"""

이상치 계산공식
# 최대 = q3 + (1.5 * IQR)
# 최소 = q1 - (1.5 * IQR)
25% 및 75% 시점의 값 추출하기
### 25% 및 75% 시점의 값 추출하기
q1, q3 = np.percentile(df["나이"], [25, 75])
q1, q3

IQR 계산
### IQR 계산
iqr = q3 - q1
iqr

### max outliners 계산
upper_bound = q3 + (1.5 * iqr)
### min outliners 계산
lower_bound = q1 - (1.5 * iqr)
upper_bound, lower_bound

이상치로 의심되는 max 또는 min을 벗어나는 데이터 추출하기
### 이상치로 의심되는 max 또는 min을 벗어나는 데이터 추출하기
df[((df["나이"] > upper_bound) | (df["나이"] < lower_bound))]

'IT > Python' 카테고리의 다른 글
| [Python] 미래 1인당 전력소비량 예측, 전기세 예측, 함수 생성, 회귀분석 그래프, 전기 단가 계산기 (0) | 2023.12.17 |
|---|---|
| [Python] 파이 차트 그리기 (2022 에너지원별 비율, 컬럼 띄우기, 간격 만들기, 색 지정하기) (0) | 2023.12.15 |
| [Python] 4. Daum 다음 영화 사이트 데이터 수집 웹크롤링 (데이터 전처리 및 시각화 워드클라우드 시각화) (3) | 2023.12.13 |
| [Python] 3. Daum 다음 영화 사이트 데이터 수집 웹크롤링 (데이터 전처리 및 시각화 원형 그래프) (0) | 2023.12.12 |
| [Python] 2. Daum 다음 영화 사이트 데이터 수집 웹크롤링 (데이터 전처리 및 시각화 막대그래프, 점(분포) 그래프) (1) | 2023.12.11 |




